Hydrogel
Tous les copolmergels ont été synthétisés par copolymérisation radicale libre en une étape de monomères avec un libellé chimique. La concentration de liaison croisée a été déterminée à 0,1% de mol27. Des solutions de DMSO contenant des monomères fonctionnels (concentration totale de 2,4 m) avec des compositions dérivées de DM et ML (tableaux supplémentaires 2 et 7), liaison croisée chimique (initiateur de glycérol 1,3-cizaine, 6 mm) ont été utilisées. Par exemple, pour préparer le gel G-MAX, 1 819 g BA, 0,413 g heh, 0,264 g de CBEA, 0,561 g ATAC, 0,441 g de pois, 8,4 mg de glycérol 1,3-duculate diacrylate et 8,8 mg 2-oxoglutarics d’acide à 10 ml volumétrique by-dms-dms-dms-dms-to-to-to-to-to-feadles. La résolution précurseur a été transférée dans une boîte à gants pour éliminer l’oxygène, versée dans une cellule de réaction (deux plaques de verre de 10 cm × 10 cm, une distance de 0,5 mm) et irradiée avec une lumière UV (longueur d’onde de 365 nm, 4 mW cm cm cm cm—2 Intensité) pendant 8 heures pour former des gels (figure supplémentaire 9a). Après le rayonnement UV, plus de 99% des monomères ont été convertis en polymères, comme confirmé par la RMN (figure supplémentaire 9b).
Les organogels préparés ont ensuite été immergés dans de l’eau salée normale (NACI 0,154 M) pour éliminer les solvants et les produits chimiques résiduels, avec une solution saline toutes les 12 heures pendant au moins 2 semaines jusqu’à ce que le gonflement de l’équilibre soit atteint. Les hydrogels ont été stockés dans une solution saline normale avant utilisation.
Caractérisation de l’adhésion sous-marine
Le test d’attaquant a été effectué à l’aide d’un testeur Shimadzu (Autographe AG-X) équipé d’un logiciel Trapezium X. Hydrogel (0,3-0,8 mm d’épaisseur) lorsque le gonflement de l’équivalence a été adhéré à la sonde en utilisant un adhésif cyanoacrylate (super colle). Pour un dépistage rapide, des hydrogels alimentés par DM à partir des hydrogels Round et ML alimentés par ML à partir de trois cycles d’optimisation ont été faits sous forme d’échantillons de 15 mm de diamètre. Pour des études d’adhésion détaillées, des échantillons de 10 mm de diamètre ont été utilisés pour éviter de dépasser la plage de puissance de l’instrument. Ce changement de diamètre n’a pas affecté les résultats de la force adhésif. L’hydrogel sur la sonde a ensuite été submergé dans une solution d’essai (par exemple, de l’eau salée normale) pendant 5 minutes pour atteindre l’équilibre. Proben est tombé vers le substrat à 1 mm min–1 Jusqu’à l’application d’une force de charge de 10 N, maintenue pendant 10 secondes et retirée à 10 mm min–1 (Fig. Supplémentaire 10). Ces conditions de test ont été utilisées comme protocole standard, sauf indication contraire. Dans les tests d’adhésion répétés, l’hydrogène repose sous l’eau pendant 5 minutes entre les cycles, avec des substrats en verre remplacés tous les 100 tests. Pour les cycles d’attachement prolongés -cycles (données élargies Fig. 8) Une force de charge de 5 N N et un temps de contact 10 s ont été utilisés pour minimiser la fatigue du gel. Chaque échantillon a été testé au moins trois fois. Pour la construction de l’ensemble de données Hydrogel, la résistance à l’adhésive la plus élevée a été enregistrée pour chaque échantillon signalé comme F-unreprésentant un avantage maximal d’adhésion dans les conditions spécifiques.
La résistance à la coupe de lecture a été mesurée à l’aide d’une machine d’essai universelle (UTM, Instron 5965). Un hydrogel (10 mm de diamètre, zone UN= 78,5 mm2) Lors de l’enflure, l’équilibre a été pressé entre deux verres en verre, pressé à 20 neuf 1 minute dans de l’eau salée normale. La charge de cisaillement a été appliquée à 50 mm min–1. Adhésif de cisaillement (F-un) a été calculé comme F-un=FMax / / UNoùFMaxest la force de charge maximale. Pour l’adhésion du test de durabilité (Fig. 15 supplémentaire), l’assemblage en sandwich a été stocké dans de l’eau salée normale pour différentes durées avant les tests.
La dureté de l’interface a été mesurée à 180 ° de tests de pelage à l’aide d’instron 5965. Des bandes d’hydrogel (10 mm × 150 mm) ont été respectées à un substrat de verre dans l’eau salée normale à l’aide de boues légères, suivis d’un rouleau à main de 2 kg appliqué dans chaque direction pendant 1 minute pour assurer un contact uniforme. Le film de polyéthylène téréphtalate (PET) (50 µm d’épaisseur) a servi de support rigide. Des tests de pelage ont été effectués à 50 mm min–1. Interface ténacité ( Gc) a été calculé commeGc = 2Fc/ / W. où Fcest le pouvoir du plateau et W.est la largeur de l’échantillon (10 mm).
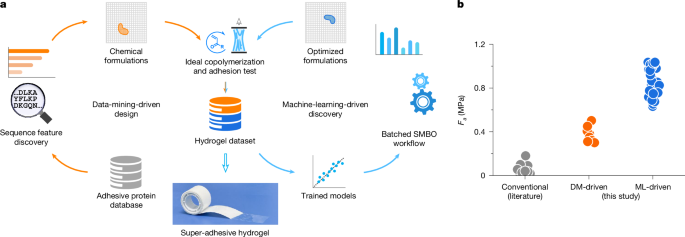
DM des protéines adhésives
Un ensemble de données complet avec des protéines adhésifs a été préparé à partir de NCBI Base de données de protéinesen utilisant des «protéines adhésives» comme mot clé de requête. Au total, 24 707 séquences de protéines de 3 822 organismes différents (bactéries, virus, eucaryotes et animaux) ont été collectées sans plus de nettoyage de données. Sur la base des commentaires de la taxonomie, les protéines ont été regroupées par des espèces et une séquence consensuelle a été générée pour chaque espèce afin de saisir des schémas de séquence ordinaire et de réduire l’impact des variations individuelles.
L’ensemble de données comprenait 3 111 espèces, notant que le chevauchement taxonomique entraîne le nombre de protéines ne résumant pas à 24 707. Pour une analyse robuste, les 200 meilleures espèces ont été classées par le nombre de protéines différentes identifiées par jour. Espèces, sélectionnées pour un examen plus approfondi.
Les séquences protéiques ont été exportées au format Fasta45 Utilisation de bio.seqio -bring à l’intérieur à Biopython46. Consensus – Les séquences ont été calculées avec Clustal Omega23Le réglage des séquences multiples fonctionne en générant une matrice d’espaceur à partir de réglages appariés, en construisant un arbre de direction basé sur des conditions évolutives et en ajustant progressivement les séquences des plus proches des plus éloignées. L’ajustement résultant identifie les restes les plus fréquents de chaque position, donnant une séquence consensuelle qui met en évidence les régions conservées.
Clustal Omega a été exécuté avec la commande:
$ W mbox {-} { rm {i}} , { rm { mbox {“ `}}} isse} { rm {f}}} { rm {i}} { rm {L}} { rm {e}}} { rm { mbox {”}} , mbox {-} mbox {-} { rm {o}} { rm {u}} { rm {t}} { rm {f}} { rm {m}} { rm {t}} , = , { rm} rm {l}} { rm {u}} , mbox {-} { rm {o}} , { rm { mbox {“ `}}} { rm {p}} { rm {u}} { rm {t}} { rm { _}} { rm {a}} { rm {l}} { rm {n}} { rm { _}} { rm {f}} { rm {i}} { rm {l}} rm {e}} { rm { MBOC aies aies aies aies aies aies aies aies aies aies aies aies aies aies aies aies aies aies aies. mbox {-} { rm {v}} $$
Où “input_file” et “output_aln_file” désignent les séquences de protéines d’entrée et les séquences de consensus de sortie. Les 200 séquences consensus générées ont été utilisées pour l’analyse de séquence ultérieure et la conception de formulation d’hydrogel.
Méthodes ML
Un vecteur de fonction à six dimensions,φje= ( φBaÀ φHuileÀ φCBEAÀ φATTAQUEÀ φAamÀ φPOIS), ont été utilisés pour représenter les proportions monomères dans l’hydrogène. La variable cible était la force adhésive, F-un . Pour modéliser la relation entre φje et F-un Nous avons exploré les modèles ML linéaires et non linéaires (tableaux supplémentaires 5 et 6).
Les modèles linéaires comprenaient au moins le retrait et la récession de l’opérateur de sélection (LASSO) et la régression de la crête (RIDG). Modèles non linéaires inclus k-Nes voisins les plus proches (KNN), régression de la crête de noyau (KRR), régression des vecteurs de support (SVR), régression aléatoire forestière (RFR), régression de boost de gradient avec XGBOost (XGB), régression supplémentaire des arbres (ETR) et procédé gaussien (GP) avec un kernel mat32.34. Ces modèles non linéaires incluent non paramétrique (KNN), basé sur le noyau (KRR, SVR et GP) et Wood Ensemble (RFR, XGB et ETR), permettant une comparaison complète34,35,47.
XGB était de V.1.6.2, tandis que les autres modèles ont été mis en œuvre en utilisant Scikit-Learn (V.1.0.2) et Scikit-Optimize (V.0.9.0). Hyperparamètre N_Stimators ont été définis à l’aide d’Optuna48Tandis que d’autres ont été optimisés en utilisant la recherche de grille (tableau supplémentaire 6). Une stratégie de validation croisée 10 fois a été utilisée pour évaluer les performances prévisibles sur notre ensemble de données de 180 hydrogels en utilisant l’erreur carrée de l’agent racine (RMSE) comme métrique. GP et RFR, avec le RMSE le plus bas dans les erreurs de test de formation utilisant une division de train / test de 90% / 10% (données étendues, figure 4), sont apparues respectivement comme les principaux praticiens et finalistes et ont ensuite été utilisés comme modèles de base (substitution).
Pour faire des prédictions extrapolatives, nous avons essayé trois types de méthodes.
-
1 et 1
Orloitation uniquement:
Dix millions φje Des vecteurs ont été générés à partir d’une distribution uniforme (0, 1,0) pour chaque monomère, normalisé à la somme à 1,0. Les cinq meilleurs vecteurs, classés par prédit F-un De chaque modèle, validé expérimentalement.
-
2
Bo lot:
-
GP_KB: a utilisé les prédictions GP comme valeurs hypothétiques pour choisir les points de données suivants qui maximisent EI.
-
Gp_clmax: utilisé le maximum F-un (y_max) dans l’ensemble de formation comme valeur hypothétique pour sélectionner les points de données suivants avec le maximum d’EI.
-
Gp_clmin: utilisé minimum F-un (y_min) pour sélectionner les points de données suivants avec le maximum d’EI.
-
GP_LP: incorporé une période localement pénalisée dans le calcul de l’IE37.
GP_KB, GP_CLMAX et GP_CLMIN LED simplifiée Q.-Ei Calcul de probabilité36 En utilisant la valeur de prédiction GP comme valeur hypothétique pour sélectionner les points de données suivants avec le maximum EI. Une taille de lot surQ.= 10 a été sélectionné.
-
-
3 et 3
Optimisation basée sur le modèle séquentiel de Batchet (SMEBO):
-
GP-RFR: GP en tant que fournisseur de valeur hypothétique et RFR comme ei-maximal.
-
RFR-RFR: RFR comme fournisseur de valeur hypothétique et maximum EI.
-
RFR-GP: RFR en tant que fournisseur de valeur hypothétique et GP comme maximiseur EI.
-
RFR-GP *: RFR-GP avec un démarrage à chaud, 10 points générés par RFR ont été ajoutés à l’ensemble de données réel pour GP GRESSION.
-
RFR-OR: RFR comme fournisseur de valeur hypothétique et ETR comme ei-maximal.
-
RFR-GBM: RFR en tant que valeur hypothétique et fournisseur GBM comme ei-maximal.
SMEBO met à jour le modèle de substitution itérative tout en explorant des points de données prometteurs33. GP et RFR lorsqu’ils sont utilisés comme fournisseurs de valeurs hypothétiques, utilisation et exploration de l’équilibre, tandis que GP_CLMAX et GP_CLMIN mettent l’accent sur l’utilisation et l’enquête,49.
-
SMEBO (algorithme supplémentaire 1) se compose de quatre composants: la vraie fonction (f), domaine mondial (X), fonction d’acquisition (S.) et modèle de substitution (M). Données de formation initiales ( D. ) est échantillonné à partir de X et expérimental F-unLes valeurs sont obtenues (ligne 1). Le modèle de substitution M est monté sur D. (Ligne 3) et S. (Ei) identifie le prochain point de données basé sur une incertitude prévisible (ligne 4). Ce point de données est ensuite validé expérimentalement (ligne 5), mise à jour D.(ligne 6) pourT.Itérations (ligne 2).
Ei quantifie l’amélioration attendue, ({ int} _ {y *} ^ { innty} (y- {y} ^ {*}) p (y) { rm {d}} y )Sur le meilleur objectif actuel ( y*). En raison de la nature à forte intensité de temps de la fabrication d’hydrogel (chacune prend environ 2 semaines) GP et RFR ont été utilisées comme fournisseurs de valeur hypothétique, permettant la maximisation de l’articulation Q.-Ei probabilité sans nécessiter de nouvelles expériences par itération. L’EI-Maximise (GP, RFR, ETR et GBM) a utilisé des hyperparamètres de Scikit Optimize (V.0.9.0).
Pour GP en tant qu’EI Maximizer, l’algorithme Limited Brouden-Fletcher-Ropes-Hannon (L-BFGS-B)50 a été réalisée 20 fois par itération (40 itérations au total) pour identifier le point avec le EI le plus élevé et mettre à jour GP auparavant. Pour les trois autres EI-Maximizes (RFR, ETR et GBM), 10 000 points ont été échantillonnés au hasard par jour. L’itération en tant qu’optimisation numérique est plus adaptée aux modèles d’ensemble en bois qui manquent d’informations sur le gradient. SMEBO a couru pour 40 itérations avec chaque maximal EI, et a sélectionné deux ensembles de 10 points de données dans chaque itération: Top 10 classé par les valeurs EI (taille du lot Q.= 10), et le top 10 classé par préditF-unValeurs pour la validation expérimentale. Ces deux ensembles se chevauchent et le nombre total de points de données peut être inférieur à 20.
Pour Bo-Methods (GP_KB, GP_CLMAX, GP_CLMIN et GP_LP), la procédure était similaire, sauf que le fournisseur de valeur hypothétique était soit GP lui-même (GP_KB et GP_LP) ou des valeurs constantes (Y_Max pour GP_CLMAX et Y_MIN pour GP_CLMIN).
Après le premier tour, 109 points validés ont élargi l’ensemble de données sur 289 hydrogels. Les deuxième et troisième tours ont ajouté respectivement 27 et 25 points, résultant en un dernier ensemble de données qui comprend 341 hydrogels.


