Les serveurs de pré-pression comme PsycharXiv ont du mal avec un contenu suspect écrit par les systèmes d’IA.Crédit: Nature
Le rapport de la prescription de la prescription: l’émergence des interfaces génératrices de l’IA dans les états de rêve de la psychologue des États-Unis Olivia Kirtley.
Alors qu’elle cliquait, sa méfiance grandissait. Le manuscrit envoyé en juillet à Psycharxiv, un lieu de recherche non révisé en revue en sciences psychologiques, ne faisait que quelques pages et répertoriait un seul écrivain dont l’attachement n’a pas été inclus. Et l’expérience de l’intelligence artificielle (IA) décrite dans le texte “était jolie”, explique Kirtley, à l’Université catholique de Louvain en Belgique.
Elle a donc marqué la prépression et similaires en tant que chefs de PsycharXiv qui les ont retirés. Le manuscrit des états de rêve a utilisé l’IA dans ses méthodes, mais n’a pas clairement déclaré comment l’IA a été utilisé ou si elle a été utilisée dans d’autres éléments de l’œuvre, ce qui signifie qu’il a violé les conditions d’utilisation du lieu, explique Dermot Lynott, chef du conseil consultatif scientifique de Psyarxiv et psychologue à l’Université Maynooth en Irlande.
En réponse aux questions de NatureUn message de l’adresse e-mail à l’auteur répertorié Jiazheng Liu a déclaré que l’IA avait joué un rôle limité dans la génération de pré-impression.

La lutte contre les fausses papiers usine qui sort de la honte scientifique
PsyarXiv n’est qu’un des nombreux serveurs de prescription – et des revues – aux prises avec des soumissions suspectes. Certains articles transportent des empreintes digitales d’usines de papier, qui sont des services qui produisent des articles scientifiques au besoin. D’autres montrent une preuve de contenu rédigé par des systèmes d’IA, tels que de fausses références, qui peuvent être le signe d’une «hallucination» de l’IA.
Un tel contenu constitue une énigme pour les services de pré-pression. Beaucoup sont des organisations à but non lucratif qui sont réservées pour faciliter la publication de leur travail, et le dépistage du contenu de faible qualité nécessite des ressources et peut ralentir le traitement des soumissions. Un tel dépistage soulève également des questions sur les manuscrits qui devraient être autorisés. Et cet afflux de contenu douteux présente ses propres risques.
“Comment faites-vous une assurance qualité tout en gardant des choses relativement faciles à toucher afin que le système ne s’effondre pas sur lui-même?” Dit Katie Corker, Connexions du comité exécutif de la société pour l’amélioration des sciences psychologiques au conseil consultatif scientifique de Psycharxiv. “Personne ne veut un monde où le lecteur individuel doit savoir si quelque chose est une bourse légitime.”
Ai – poussée de croissance
Les services de pré-pression qui sont contactés par Nature a déclaré qu’une partie relativement petite de leurs soumissions a des signes de génération par un modèle de langue (LLM) en grande langue en tant que celui qui conduit Openais Chatgpt. Par exemple, les opérateurs du serveur Preprint ArXIV estiment que environ. 2% de leurs soumissions sont rejetées comme des produits de l’IA, des usines de papier ou les deux.
Richard Sever, leader d’OpenRxiv, qui anime le serveur de vie de vie biorxiv et le serveur biomédical Medrxiv, basé à New York, affirme que les deux ont combiné plus de dix manuscrits par an. Jour qui semble formel et peut avoir été généré par l’AI. Les services reçoivent environ. 7 000 soumissions par mois.

AI lié à l’explosion des articles de recherche biomédicale de basse qualité
Mais certains disent que la situation semble empirer. Les modérateurs d’Arxiv ont remarqué une augmentation du contenu écrit peu de temps après le lancement de Chatgpt à la fin de 2022, mais “nous avons vraiment commencé à penser qu’il y a eu une crise au cours des trois derniers mois”, explique Steinn Sigurðsson, directeur scientifique chez Arxiv et astrophysicien à la Penn State University à University Park.
DANS Une déclaration envoyée le 25 juilletLe Center for Open Science, une organisation à but non lucratif à Washington DC, qui héberge Psyarxiv, a déclaré qu’il “avait vu une augmentation notable des articles soumis qui semblent générés ou fortement aidés par des outils d’IA”. Lynott confirme qu’il y a eu une “petite augmentation” sur le site et que le serveur travaille pour minimiser ce contenu.
Les défis de la modération de la prépression ont été démontrés par le manuscrit de l’État de rêve marqué par Kirtley: peu de temps après la suppression de la pré-pression, un titre presque identique et un résumé a été placé sur place. Un e-mail de l’adresse associée à l’auteur a déclaré que “le rôle de l’IA était limité aux dérivations mathématiques, aux calculs symboliques, à la collecte et à l’utilisation d’outils mathématiques existants, à la confirmation de la formule” et huit autres tâches. L’auteur de l’e-mail s’est décrit comme un “chercheur indépendant basé en Chine” sans un degré d’éducation plus élevé et si “seul outil est un smartphone d’occasion”. La deuxième version de la pré-pression est également supprimée.
Aiders de chatbot
Une étude1 Publié la semaine dernière dans Nature comportement humain Estime qu’en septembre 2024, les LLM, près de deux ans après le déploiement de Chatgpt, ont produit LLMS 22% du contenu des résumés informatiques-scientifiques qui ont été disposés sur ArXIV et env. 10% du texte des résumés de biologie envoyés sur Biorxiv (voir «Rise of the Chatbot»). En comparaison, une analyse2 Des résumés biomédicaux publiés dans des revues en 2024 ont révélé que 14% avaient un texte généré par LLM dans leurs résumés.
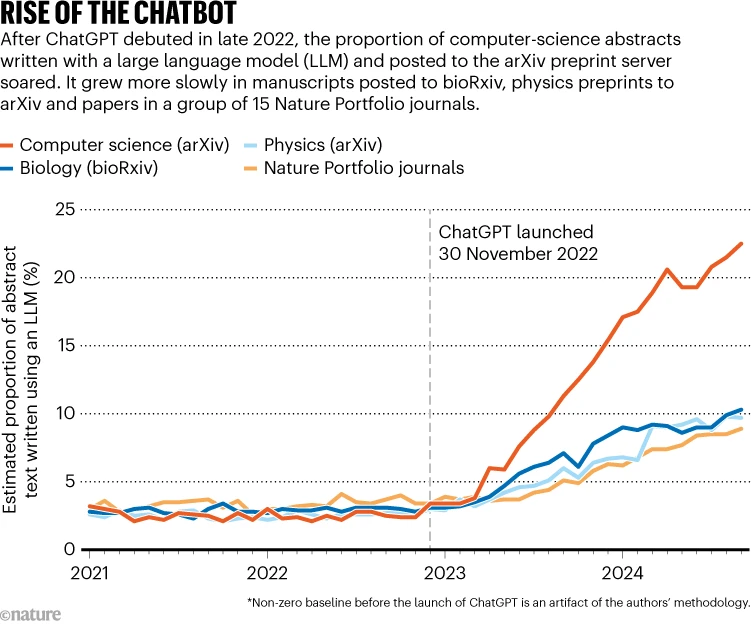
Source: Réf 1.
Une partie du texte de l’IA rapporté dans l’étude aurait pu être générée par des chercheurs qui se battraient autrement pour écrire un manuscrit en anglais, explique James Zou, informaticien de l’Université de Stanford en Californie et co-auteur de Nature comportement humain papier.